Can Machines Discover?

Discovery Engine — Post #1
The Question
In 1950, Alan Turing asked whether machines could think (Turing, 1950). That question gave artificial intelligence a direction, a test, and a destiny — and defined the field for the seven decades that followed. It was not answered by argument. It was answered — or rather, transformed — by demonstration.
Turing himself acknowledged, in the opening pages of Computing Machinery and Intelligence, that the question taken literally was probably not the right one to argue about. The meaning of "think" had been contested for centuries and would not be settled by computer science. He replaced it with something operational — the imitation game — and left the rest for the next seventy years to decide.
Seventy-five years later, I wish to pose a successor question. It is, in part, a tribute to Turing's. But as I will argue, it is also something fundamentally different — and one I believe is both more tractable and more significant:
Can Machines Discover?
And alongside it, a second question that this article will argue is equally important:
What kind of science are we doing now — and is it adequate to the problems we face?
The two questions are inseparable. The case for machine discovery rests, at its foundation, on an account of the limits of human science — a claim that the cognitive architecture of human scientists, and the institutional structures within which they work, systematically constrain the scope and depth of what science can discover. The account is developed in the sections that follow.
This is the opening of Discovery Engine.
Why "Discover" Comes After "Think"
On the surface, my question looks like a small step from Turing's. Both ask whether machines can perform a kind of cognition long taken to be uniquely human. But the interior of the two questions is profoundly different.
Turing asked whether machines could simulate humans.
I am asking whether machines can transcend them.
A machine that thinks like a human is bounded by human cognition — by the architecture of our brains, the curvature of our attention, the gravity of our cultural priors. Whatever such a machine reaches is, in the end, something a human reach was already pointed toward.
A discovering machine may not be bounded that way at all. The working hypothesis of this blog is:
A discovering machine is bounded only by the structure of reality itself.
This is the largest claim I want to defend across the posts that follow.
Think and Discover Are Not the Same Kind of Act
The difference between thinking and discovering deserves careful unpacking, because it is tempting to read them as adjacent capabilities — as if discovery were merely thinking applied to a harder problem. It is not.
Think describes a family of operations within an existing space of concepts: inference, conversation, problem-solving, symbolic manipulation, planning. These are operations over a representation. They presuppose that the relevant terms, categories, and relations are already in place. A system that thinks moves around inside a conceptual room whose walls have already been built.
Discover is different in kind. Discovery is the act of producing something that was not previously contained in the available space of concepts. It introduces a new object — a fact, a mechanism, a relation, sometimes an entire conceptual coordinate system — into the body of human knowledge. It is:
- the surfacing of a structure that was not previously visible;
- the generation of an explanation that the prior conceptual vocabulary did not support;
- and, on occasion, the redrawing of the conceptual axes themselves — what philosophers of science have called a paradigm shift (Kuhn, 1962).
In a phrase: thinking moves within a space of meaning. Discovery enlarges that space — sometimes by adding new positions within it, sometimes by extending its boundaries, and at its limit, by generating new semantic dimensions altogether.
This reframing has a consequence Turing's question did not have. Can Machines Think? progressively dissolved the boundary between human and machine cognition; the better machines became at simulating us, the less clear it became where "we" ended. Can Machines Discover? runs the opposite direction. It throws the question back at us. Before we can answer whether machines can discover, we have to answer what discovery actually is — whether it is intuition, embodied judgment, a social process, a form of simulation, an act of compression, an update to an internal model of the world, or something we have never quite succeeded in naming.
In that sense the new question is more demanding than the old. Turing's resolved itself, in practice, through demonstration: at some point machines simply began doing the thing. Mine cannot fully resolve itself until we understand the act it asks about.
Three Classes of Discovery
It would be misleading to leave the impression that discovery means only the dramatic redrawing of conceptual axes. The vast majority of scientific discovery, by volume and arguably by cumulative significance, takes other forms — and any honest account of what an autonomous discovery system would do must take all of them seriously.
Discoveries can usefully be sorted into three classes, ordered by conceptual scope.
Class I — Pieces of Knowledge. New facts, data points, or relationships that fit within existing frameworks. The discovery of a new element. The identification of a previously unknown exoplanet. The characterization of a previously uncharacterized gene. A new measurement that pins down a previously uncertain quantity. These do not change how we see the world; they expand the collection of known pieces within it. By count, this is what most of science is, and there is nothing diminished about that. Every Class II and Class III discovery rests on a substrate of Class I discoveries.
Class II — Frameworks for Specific Phenomena. A new framework that organizes and explains a specific class of events. Germ theory of disease. Plate tectonics. The cell-cycle checkpoint — the concept of a regulatory pause-point that, once named, suddenly organized a scattered set of observations about how cells decide whether to proceed through division. Cooper pairs and the BCS theory of superconductivity. Bose–Einstein condensation. Specific reaction mechanisms in chemistry. What these share is that an act of conceptualization — often the naming of a previously unnamed organizing principle — makes a scattered body of observations suddenly coherent. Before the term "checkpoint," the cell-cycle literature was a catalog of pause-and-resume behaviors; after, those behaviors were instances of a single regulatory category. These are not new physical laws. They are new maps for previously unmapped territory.
Class III — New Ways of Seeing. A fundamentally new perspective that redefines what we understand reality to be. Relativity. Natural selection. Quantum mechanics. Gauge theory — the realization that the fundamental forces of nature are not inherent properties by which one body acts on another, but the visible consequence of local symmetries, mediated by the exchange of gauge particles. Systems thinking. These are rare. They are the discoveries that produce paradigm shifts in Kuhn's strict sense (Kuhn, 1962). What distinguishes Class III is that the redefinition reaches the categories themselves. Before gauge theory, a "force" was a property; after, a force was what we called the consequence of a symmetry. The phenomena did not change. What counted as an explanation did. Class III discoveries are also, in part, the discoveries from which Class I and Class II discoveries inherit the conceptual vocabulary that lets them be intelligible at all.
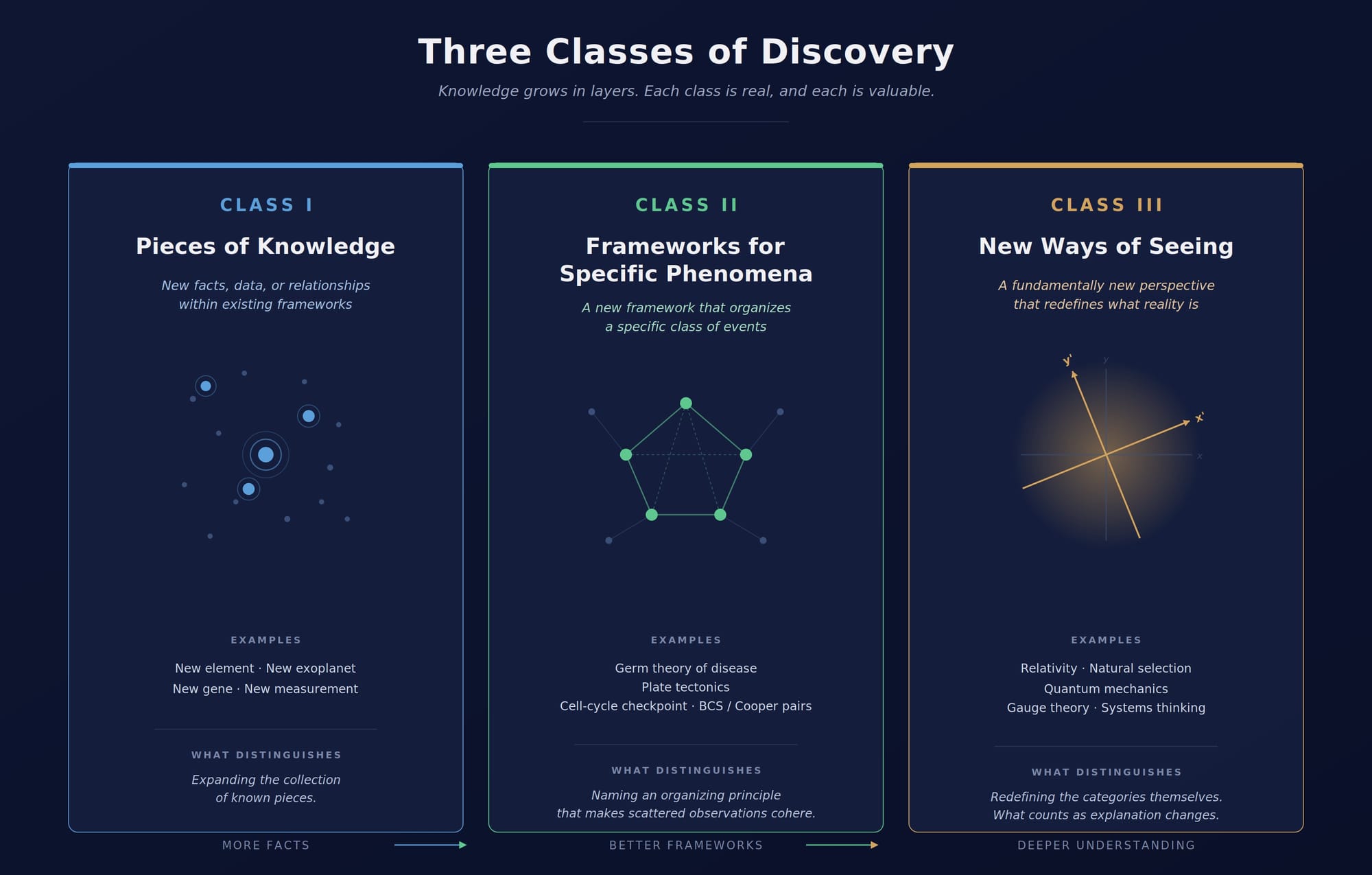
The traffic between the three is two-directional. Facts demand frameworks. Frameworks demand new facts to test them. Plate tectonics emerged from countless prior measurements of seismic activity, ocean-floor magnetism, and continental geometry. Relativity rested on Michelson and Morley's precise measurement of the speed of light. And once in a generation, the friction between the classes produces a Class III shift.
The case for machine discovery does not rest on Class III alone. In some respects, the most immediate and most defensible case is for Class I — and that matters, because Class I is where the bias of human science is most visible, and where the comparative advantage of autonomous systems is sharpest. Machines bring three things to Class I that human science structurally cannot scale: precision at the limits of measurement, with consistent and reproducible results; long-tail coverage of the rare events, unstudied conditions, and combinatorial regions that no individual lab has the bandwidth to reach; and lower cost per experiment, by orders of magnitude.
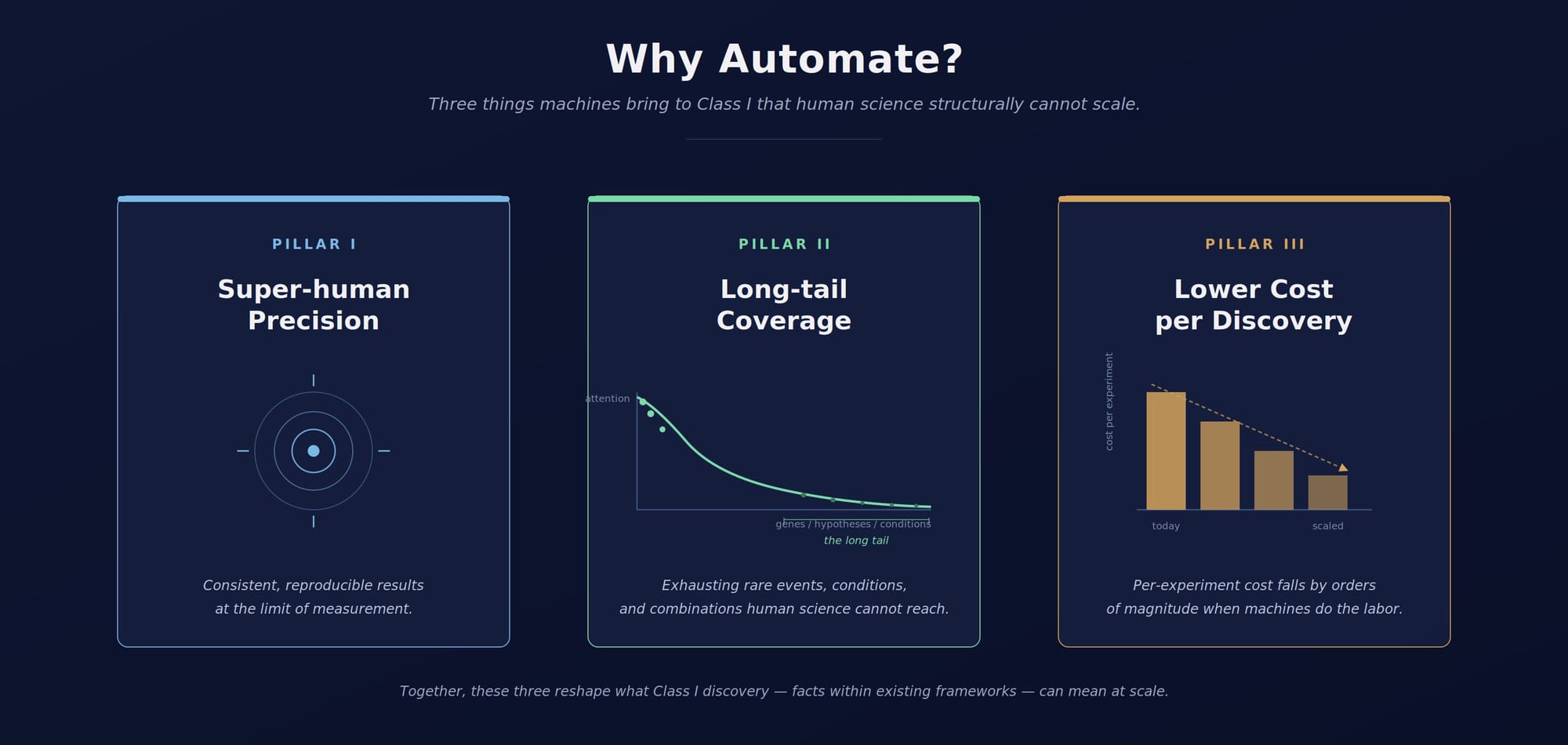
The TREM2 case is exactly that. TREM2 is a Class I discovery — a fact about a specific gene's relationship to a specific disease — that sat unmade for decades because the human attention economy systematically refused to bet on it. The 96.8% figure (Stoeger et al., 2018) tells us many more such facts are waiting: in the long tail of the genome, in the unexplored regions of chemical space, in the space of possible material compositions, in the conditions and combinations no individual lab has the bandwidth to test. Most of them are Class I. Most of them are valuable. Almost none of them will be found by the current paradigm.
If autonomous discovery systems did nothing more than work the long tail of Class I at the scale, precision, and consistency that machines make possible, that alone would constitute a transformation of science. Class II and Class III, if they come, will be a further matter — and we will return to them.
A Tractable Question, in Another Sense
The three-class picture also clarifies what kind of question Can Machines Discover? really is, and why it is in one important sense more tractable than Turing's.
Turing's question had a metaphysical floor beneath it. Does this machine truly think? — pushed hard enough — descends into the deepest waters of philosophy. What is consciousness? What is understanding? What is meaning? John Searle's Chinese Room argument, advanced in 1980, sharpened this exactly. Imagine a person locked in a room, equipped with an exhaustive rulebook for manipulating Chinese symbols. Chinese-language questions are passed in through a slot; following the rules, the person produces fluent Chinese answers and passes them back out. To anyone outside, the room appears to understand Chinese. The person inside understands nothing. Searle's claim was that a system can produce outputs indistinguishable from those of a thinking being while harboring no inner understanding whatsoever (Searle, 1980). We have argued about that thought experiment for forty-five years. We have not converged. We will not.
Discover sidesteps that floor. Discovery has externally measurable consequences across all three classes: it produces knowledge that is novel, verifiable, and significant. The scientific community has a long, imperfect, but functioning practice for telling the difference. Yamanaka's discovery of induced pluripotent stem cells was a real discovery (Takahashi & Yamanaka, 2006). Charpentier and Doudna's elucidation of CRISPR-Cas9 as a programmable editing tool was a real discovery (Jinek et al., 2012). The detection of the Higgs boson was a real discovery. None of these judgments depends, in principle, on whether the discoverer was a human, a machine, or a hybrid of the two.
That is what I mean when I call Can Machines Discover? an empirical question — empirical in the sense that the answer is settled by evidence in the world, not by argument over definitions. We do not need to agree on what discovery "really is" in order to recognize, when it occurs, that something has been discovered. The verdict is rendered the way the scientific community has always rendered it: by examining the result, testing it, and accepting or rejecting it on grounds of consequence.
This is what makes the question ambitious enough to organize a field, and specific enough to permit measurable progress — the two conditions any grand challenge must satisfy (Kitano, 2016, 2021).
We Are Already Navigating in the Dark
There is also a more consequential reason to pose the question now.
Roughly two million papers are published in the biomedical sciences each year. In the most active subfields, the rate exceeds a thousand per day. No human scientist can read them all, integrate them coherently, or recognize the connections that matter. We have built a cathedral of knowledge so vast that no single mind can perceive its overall shape. We navigate it by local landmarks, largely unaware of the global structure.
This is not information overload. It is something more troubling: structural misalignment.
And the shape of that misalignment is measurable. The human genome contains roughly 40,000 annotated genes. Sample 100 of them at random, pull their PubMed records, and a striking pattern emerges: 96.8% of the publications in the sample cluster on a small subset of well-studied genes. This is consistent with the systematic bias documented across the entire ~19,000 protein-coding gene set by Stoeger and colleagues (Stoeger et al., 2018).
The bias is not difficult to explain — and that, in itself, is part of the problem.
Scientists, like everyone else, want to succeed, and they want to contribute. Choosing to work on a gene that already appears important is a rational career strategy: prior signals of significance attract funding, reviewers, citations, and trainees. The same incentive operates in the original choice of research direction. Researchers gravitate toward problems that look likely to matter — because they want to do work that matters, and because the institutions that support them reward work whose mattering is already legible. This is not vice. In most respects it is virtue. But its aggregate effect, summed across a global research community, is a strong concentration of attention on what is already visibly important.
Conversely, working on a gene from the long tail — a gene with no prior signal of significance — is, for an individual researcher, an unreasonable bet. The expected payoff is low. The grant is harder to write. The paper is harder to place. If the gene turns out to matter, the vindication may not arrive for fifteen years. Most career trajectories cannot absorb that kind of latency. And so the long tail goes unworked — not because it has been examined and dismissed, but because it has not been examined at all.
This is, in a precise sense, a cognitive and sociological bias of human science. It is not a failure of any individual scientist. It is a predictable signature of the kind of agent — career-bearing, mortality-bound, status-sensitive, risk-averse on long horizons — that human scientists are.
The cost of this bias is not theoretical. TREM2, a microglial receptor whose rare variants we now know roughly double the risk of late-onset Alzheimer's disease (Guerreiro et al., 2013; Jonsson et al., 2013), spent decades in the long tail, essentially unread. It is improbable that it is the only such case. The 96.8% figure implies the existence of a great many more.
If this distribution is not accidental — if it is the predictable signature of how human science allocates attention given the cognitive, sociological, and economic structures within which scientists work — then the distortion cannot be corrected from inside the current paradigm. The paradigm produced it.
What "Discovery Engine" Means
The title of this blog is at once a metaphor and a technical proposal.
As metaphor: the steam engine industrialized manufacturing in the late eighteenth century. AI-and-robotics systems running closed-loop scientific experimentation may industrialize discovery itself. Discovery has remained, structurally, a pre-industrial enterprise — performed by skilled individuals, one hypothesis at a time, bounded by the cognitive throughput of a single mind. The engine is what comes next (Kitano, 2016, 2021).
The pieces are already in evidence. Ross King's robotic scientist Adam & Eve are early demonstrations that the full hypothesis–experiment–revision cycle can be made autonomous in narrow domains (King et al., 2009; Sparkes et al., 2010). AlphaFold has shown that a single AI system can absorb a global problem space — protein structure — that no individual human could have characterized in a career (Jumper et al., 2021). AlphaGo and its successors have demonstrated that machine search, properly architected, can find moves no human grandmaster would have considered, in spaces previously thought to require human intuition (Silver et al., 2016). These are pieces. The engine itself — the integrated, closed-loop architecture that would let these capabilities operate together at scale — does not yet exist. I have called it the Warp Drive for Scientific Discovery. It needs to be built.
As technical proposal: the engine takes the concrete form of the Nobel Turing Challenge — to build, by 2050, an AI system capable of making discoveries worthy of the Nobel Prize, with a high degree of autonomy (Kitano, 2021). The prize itself is not the point. The prize is the yardstick. What we care about is the caliber of discovery, and the Nobel Prize is the most defensible existing proxy for it.
The Challenge is the operational form of Can Machines Discover? It is what makes the question testable rather than merely aspirational. And it stands in a continuous line with the grand-challenge tradition in artificial intelligence — from the chess machines of the 1950s, through Deep Blue, through AlphaGo, through RoboCup (Kitano et al., 1997). Each of those challenges was answered, in the end, by demonstration rather than by argument. The Nobel Turing Challenge will, I suspect, be answered the same way.

This blog will work through what that means, post by post:
- The limits — why human science is encountering its own structural limits;
- Connecting Distant Dots — Paths that connect distant observations, concepts, and fields to generate new discoveries;
- The architecture — what a closed-loop autonomous discovery system actually consists of;
- The benchmark — the Nobel Turing Challenge: what it tests, and how;
- The epistemology — what science becomes once machines begin to do it;
- The human role — what role human scientists play when they are no longer the engine.
This is neither a clean story of replacement nor a tidy story of partnership. In many cases — likely most — humans will sit outside the operational loop: the machine will read, hypothesize, design, execute, and verify without us. What remains for human scientists is real but more specific than the present arrangement implies. The first role is alignment — deciding which of the things a machine can discover are the things that matter to humans, and which of those get surfaced, prioritized, applied. The second is the niches — regions of the scientific landscape that, for reasons of cost, embodiment, access, or sheer specificity, machine systems will not reach. These two roles are not consolation prizes. They are what becomes scarcest, and therefore most valuable, once search and throughput are no longer the bottleneck.
A Prediction
In Computing Machinery and Intelligence, Turing offered a prediction: within fifty years, machines would play the imitation game well enough to fool an average interrogator most of the time. On any reasonable reading, that prediction has come true.
I will hazard one of my own:
Just as Turing's question was answered not by argument but by demonstration, Can Machines Discover? will be answered the same way. One day, the scientific community will recognize a discovery as genuine and significant — and will look back to find that no human played a load-bearing role in producing it.
On that day, the question moves into the past tense.
And on that day, the harder question begins:
Will machine discoveries look like ours, or will they look like something else entirely?
There is a baseline answer to this that is, by itself, transformative. Autonomous systems working systematically across the long tail of Class I discoveries — the facts human science has structurally underweighted — will produce more verified new knowledge in the coming decades than the existing paradigm has produced in the entirety of its history. The TREM2-shaped gaps will be filled in, at scale, with mechanical patience. That alone would be a revolution in what science can reach.
But the deeper possibility goes further. Machines may not stop at Class I. They may begin building Class II frameworks across domains where no human team has had the bandwidth to assemble them — synthesizing across literatures that humans have, by structural necessity, kept separate. And at the limit, they may begin generating new semantic dimensions — new ways of carving the world, new axes along which to organize phenomena, new categories of what counts as a question worth asking. If discovery, taken at its furthest reach, is the act by which the conceptual space of science enlarges itself, then a sufficiently capable discovering machine will participate in that enlargement too.
My intuition is that machine discoveries will not look like ours. A system that explores by exhaustive search, by combining literatures no human team has ever combined, by attending to features of the scientific landscape that human salience-detection systematically suppresses, will not arrive at the same insights along the same paths. It will arrive at adjacent territories, by adjacent routes. Some of what it finds will be unrecognizable to us at first — not because the discoveries are wrong, but because the semantic dimensions they inhabit are not yet ours.
What we will then have learned is not only something about machines. It will be something about discovery itself — about what kind of act we have been performing all along, when we did it ourselves.
The machines are already starting to ask questions humans never thought to ask.
A new paradigm of discovery is emerging.
A Note on How This Was Written
Discovery Engine has a second premise, and I want to state it up front rather than bury it in a footnote.
This blog is written by a human author (Hiroaki Kitano) working in deep collaboration with AI systems. My primary collaborator is Claude (Anthropic), with Gemini (Google) as the secondary collaborator and ChatGPT (OpenAI) also in the loop for cross-checking, alternative framing, and reference work. Drafts move between us. Arguments are stress-tested. Structures are rebuilt. Phrasings are sharpened. The final editorial judgment — what to say and what to leave out — is mine. The thinking, in the broader sense, is shared.
This is intentional, and it is on-theme.
A blog asking whether machines can discover would be evasive if it pretended to be written by a human alone. The honest position is that this is what serious human–machine collaboration already looks like in 2026 — at the writing layer, which is the easiest layer. The discovery layer is harder. The discovery layer is where this blog is going.
What you are reading is a small data point on what is already possible. The posts that follow will be about what is not yet possible — and what it will take to get there.
Hiroaki Kitano, Co-authored with Claude (Anthropic, primary), Gemini (Google, secondary), and ChatGPT (OpenAI).
See the Lab Notebook for this post for source materials, iteration history, AI inputs, and what we learned.
References
Guerreiro, R., et al. (2013). TREM2 variants in Alzheimer's disease. New England Journal of Medicine, 368(2), 117–127. https://doi.org/10.1056/NEJMoa1211851
Jinek, M., Chylinski, K., Fonfara, I., Hauer, M., Doudna, J. A., & Charpentier, E. (2012). A programmable dual-RNA-guided DNA endonuclease in adaptive bacterial immunity. Science, 337(6096), 816–821. https://doi.org/10.1126/science.1225829
Jonsson, T., et al. (2013). Variant of TREM2 associated with the risk of Alzheimer's disease. New England Journal of Medicine, 368(2), 107–116. https://doi.org/10.1056/NEJMoa1211103
Jumper, J., et al. (2021). Highly accurate protein structure prediction with AlphaFold. Nature, 596, 583–589. https://doi.org/10.1038/s41586-021-03819-2
King, R. D., et al. (2009). The automation of science. Science, 324(5923), 85–89. https://doi.org/10.1126/science.1165620
Kitano, H., Asada, M., Kuniyoshi, Y., Noda, I., & Osawa, E. (1997). RoboCup: The robot world cup initiative. AI Magazine, 18(1), 73–85. https://doi.org/10.1609/aimag.v18i1.1276
Kitano, H. (2016). Artificial intelligence to win the Nobel Prize and beyond: Creating the engine for scientific discovery. AI Magazine, 37(1), 39–49. https://doi.org/10.1609/aimag.v37i1.2642
Kitano, H. (2021). Nobel Turing Challenge: Creating the engine for scientific discovery. npj Systems Biology and Applications, 7, 29. https://doi.org/10.1038/s41540-021-00189-3
Kuhn, T. S. (1962). The Structure of Scientific Revolutions. University of Chicago Press. University of Chicago Press
Searle, J. R. (1980). Minds, brains, and programs. Behavioral and Brain Sciences, 3(3), 417–457. https://doi.org/10.1017/S0140525X00005756
Silver, D., et al. (2016). Mastering the game of Go with deep neural networks and tree search. Nature, 529, 484–489. https://doi.org/10.1038/nature16961
Sparkes, A., et al. (2010). Towards Robot Scientists for autonomous scientific discovery. Automated Experimentation, 2, 1. https://doi.org/10.1186/1759-4499-2-1
Stoeger, T., Gerlach, M., Morimoto, R. I., & Amaral, L. A. N. (2018). Large-scale investigation of the reasons why potentially important genes are ignored. PLOS Biology, 16(9), e2006643. https://doi.org/10.1371/journal.pbio.2006643
Takahashi, K., & Yamanaka, S. (2006). Induction of pluripotent stem cells from mouse embryonic and adult fibroblast cultures by defined factors. Cell, 126(4), 663–676. https://doi.org/10.1016/j.cell.2006.07.024
Turing, A. M. (1950). Computing machinery and intelligence. Mind, 59(236), 433–460. https://doi.org/10.1093/mind/LIX.236.433
How to cite this article
Kitano, H. (2026). Can Machines Discover? Discovery Engine, May 27, 2026. https://thediscoveryengine.ai/can-machines-dis/
BibTeX:
@misc{kitano2026machines,
title = {Can Machines Discover?},
author = {Kitano, Hiroaki},
year = {2026},
month = {May},
day = {27},
howpublished = {\url{https://thediscoveryengine.ai/can-machines-dis/}},
note = {Discovery Engine, Post \#1}
}


