機械は発見できるか (Can Machines Discover?)

Discovery Engine — Post #1 — 日本語版
はじめに
1950 年、Alan Turing は「機械は思考できるか (Can Machines Think?)」という問いを立てた (Turing, 1950)。この問いは、その後の 70 年にわたって人工知能という分野を定義してきた。方向を示し、試金石を与え、ある種の運命を背負わせた。だが、この問いに決着をつけたのは議論ではない。Demonstration だった。いや、より正確に言うなら、demonstration が問いそのものを変えていった、というべきだろう。
Turing 自身も Computing Machinery and Intelligence の冒頭で認めている。この問いを字義どおりに受け取って議論を始めるのは、おそらく適切ではないと。「思考する (think)」という語の意味は何世紀も争われてきたものであり、計算機科学がそこに決着をつけられる見込みはなかった。だから彼は、問いを模倣ゲーム (imitation game) という具体的な手続きに置き換え、残りは続く 70 年の判断に委ねた。
それから 75 年。ここで、その後継となる問いを立てたい。Turing の問いへのオマージュであると同時に、ここから論じていくとおり、根本的に異質な問いでもある。この新しい問いの方が、より結果が明確であり、重要性も高いと考えている。
機械は発見できるか (Can Machines Discover?)
そしてもう一つ、本稿が同じくらい重要だと主張する問いを並べる。
私たちはいま、どのような種類の科学を行っているのか —— そしてそれは、私たちが直面する問題に対して、十分なものなのか?
この二つは切り離せない。機械による発見を加速するべきだという議論は、その根底に、人間の科学についての限界論を持っている。人間の科学者がどのように考え、どのような制度の中で働いているか —— その構造そのものが、科学が到達できる範囲と深さを系統的に縛っている、という分析だ。その分析の中身は、続く節で展開していく。
これが Discovery Engine の出発点である。
なぜ「思考」の次が「発見」なのか
表面的には、私の問いは Turing の問いから半歩しか離れていないように見えるかもしれない。どちらも、長く人間固有とされてきた知的な営みを、機械が為しうるかを問うている。だが、二つの問いの内側は、まったく違う。
Turing は、機械が人間を 模倣 できるかを問うた。私は、機械が人間を 超え られるかを問うている。
人間のように考える機械は、人間の認知に縛られる。私たちの脳の作り、注意の向け方、文化のなかで身につけたバイアス、その「重力」に。そういう機械が辿り着くものは、結局のところ、人間の手がすでに伸びていた方向にある何かでしかない。
だが、「発見する機械」は、そうは縛られないかもしれない。本ブログを通して検討したい中核の仮説は、こうである。
発見する機械を縛るのは、ただ現実 (reality) の構造そのものだけかもしれない。
これが、続く諸投稿を通して擁護したい、最大の主張である。
「思考」と「発見」は同じ種類の営みではない
「考える」と「発見する」の違いは、丁寧にほぐすに値する。発見というのは難しい問題に向けた思考の一種にすぎない —— そう読んでしまうのは、たやすい。だが、両者はそもそも違う種類の行為である。
考える というのは、すでにある言葉と概念の中で動き回ることだ。推論、対話、問題解決、記号操作、計画。どれも、すでに名前のついた対象とその関係を使って行う作業である。語彙が整っていて、カテゴリが決まっていて、関係性が分かっている。そうでなければ、考えるという作業そのものが始まらない。考える機械は、すでに壁が組み上がった部屋の中を歩き回っている。
発見する というのは、これとは違う。発見とは、これまで誰も持っていなかったものを、世に出す行為である。新しい事実、新しいしくみ、新しい関係 —— ときには、世界の見方そのもの。それは:
- これまで見えていなかった構造を、見えるようにする行為であり、
- これまで使ってきた言葉では言い表せなかったものを、言葉にする行為であり、
- ときには、何を観察し、何を測り、何を問題と呼ぶか、その基準そのものを引き直す行為でもある —— のちに科学哲学が パラダイム・シフト (paradigm shift) と呼ぶことになるもの (Kuhn, 1962)。
一行にすれば、こうだ。思考は、すでにある考え方の中を動くこと。発見は、その考え方の範囲そのものを広げることだ。新しい事実を加えるだけのこともあれば、考え方の枠そのものを押し広げることもある。そして最も大きな発見では、世界をどう見るかという見方そのものが、新しく作り出される。
この違いは、Turing の問いには持てなかった一つの帰結を伴う。「機械は思考できるか」は、時間が経つにつれて、人間と機械の境界を溶かしていった。機械が人間を模倣することに長けるほどに、「私たち」がどこで終わるのかは、曖昧になっていった。「機械は発見できるか」は、逆の向きに作用する。問いを、こちら側に投げ返してくるのだ。機械が発見できるかを答える前に、まず答えなければならないことがある —— 発見とは、そもそも何か を。直観なのか、身体に染みついた判断なのか、社会的な営みなのか、ある種のシミュレーションなのか、情報を凝縮する作業なのか、世界についての心のなかの地図を書き換える作業なのか、それとも、私たちがまだ十分に名指せていない何かなのか。
その意味で、新しい問いは、古い問いより一段、要求が厳しい。Turing の問いは結局のところ、demonstration によって自分自身で決着していった。ある時点で、機械が単純にそれを始めたからだ。一方、私の問いは、そう簡単には決着しない。「機械が発見できるか」に答えるためには、まず「発見とは何か」を私たちが分かっていなければならないからだ。
発見の三つのクラス
「発見」というと、概念の座標軸を劇的に引き直すような出来事ばかりを思い浮かべてしまう。だが、それは誤導だ。実際の科学的発見は、件数で見ても、積み上げる意義の総和で見ても、その大半は別の形をとっている。自律的に発見を行うシステムを真面目に構想するなら、その「別の形」もきちんと扱わなければならない。
発見を、概念の届く範囲によって三つに分けると整理しやすい。
Class I —— 知識のピース。 既存の枠の中に新しく加わる事実、データ、関係。新しい元素の発見。新しい系外惑星の同定。それまで未解析だった遺伝子の機能の特定。それまで誤差の幅が大きかった量を、正確に測り直す。これらは世界の見方を変えるものではなく、すでにある世界の地図に、新しい点や線を書き加える行為である。件数で言えば、科学のほとんどはこれだ。そして、それを矮小化する必要はない。Class II も Class III も、Class I の積み重ねがなければ成り立たない。
Class II —— ある現象に対する新しい枠組み。 ばらばらに観察されていた現象を、まとめて説明する考え方を提案する。病気の細菌説。プレートテクトニクス。細胞周期の checkpoint —— 細胞が分裂を進めるかどうかを「いったん止めて確かめる」というしくみがあると分かった瞬間、それまで散らばっていた観察が、一つの調節原理の現れとして整理された。超伝導の BCS 理論における Cooper pair。ボース・アインシュタイン凝縮。化学における特定の反応機構。共通するのは、概念に「名前を与える」という行為 —— それまで名指されていなかった整理の原理に名前がつくと、散らばっていた観察が、一つのカテゴリの実例として急に見えるようになる。「checkpoint」という語が定着する前、細胞周期の文献は「いったん止まる現象、いったん再開する現象」の目録だった。語が定着したあと、それらは一つの調節カテゴリの実例になった。新しい物理法則ではない。それまで地図のなかった領域に、地図ができた、ということだ。
Class III —— 世界の見方そのものの作り直し。 何を現実とみなすかの枠そのものを書き換える発見。相対性理論。自然選択。量子力学。ゲージ理論 —— 自然界の基本的な力は、ものに最初から備わった性質ではなく、局所的な対称性 (local symmetry) の結果として、ある粒子のやりとりを介して現れるもの、と捉え直された瞬間。システム思考。これらは稀である。Kuhn が厳密な意味で「パラダイム・シフト」と呼んだ種類の発見だ (Kuhn, 1962)。Class III が他と違うのは、書き換えがカテゴリそのものに及ぶことだ。ゲージ理論以前、「力」とは物体に備わる属性だった。ゲージ理論以後、「力」とは対称性の帰結を呼ぶ名前になった。観察される現象は変わっていない。だが、「それを説明する」とはどういうことか、が変わった。Class III はまた、Class I や Class II が拠って立つ概念の語彙そのものを、後の世代に手渡す発見でもある。
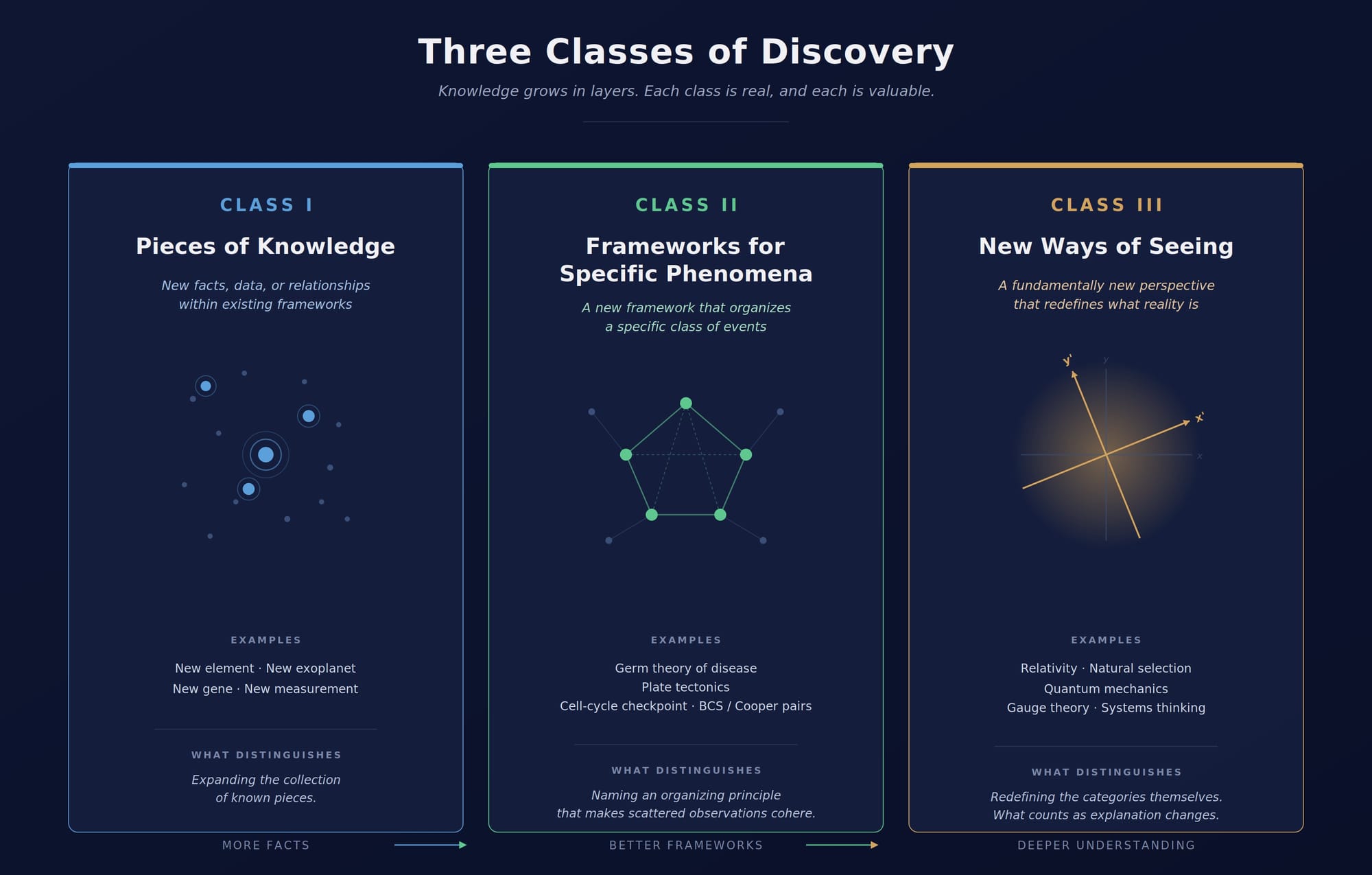
この三つの間には、双方向の行き来がある。事実が積もると、それを整理する枠組みが必要になる。枠組みは、それを試すための新しい事実を必要とする。プレートテクトニクスは、地震、海底磁気、大陸の形といった、膨大な事前の測定の上に立っている。相対性理論は、Michelson と Morley による、光の速度の精密な測定の上に立っている。そしてごく稀に、事実が既存の枠組みでは整理しきれなくなったとき、世界の見方そのものを書き直す Class III の発見が起きる。
機械による発見は、Class III だけを目指すものではない。最も即効性があり、最も論証しやすいのは、むしろ Class I である。そしてこれは重要だ。Class I こそ、人間の科学の偏りが最も目に見える場所であり、自律的なシステムの比較優位が最も鋭く立ち上がる場所だからだ。Class I に対して機械が持ち込めるものは、人間の科学では構造的に拡張しにくい三つの特徴である —— 測定の限界における 精度、再現可能で一貫した結果、誰もカバーしていないロングテール(rare events、まだ手のつけられていない条件、組み合わせの広大な空間)に対する 網羅性、そして実験ひとつあたりの コスト が桁違いに低いこと。
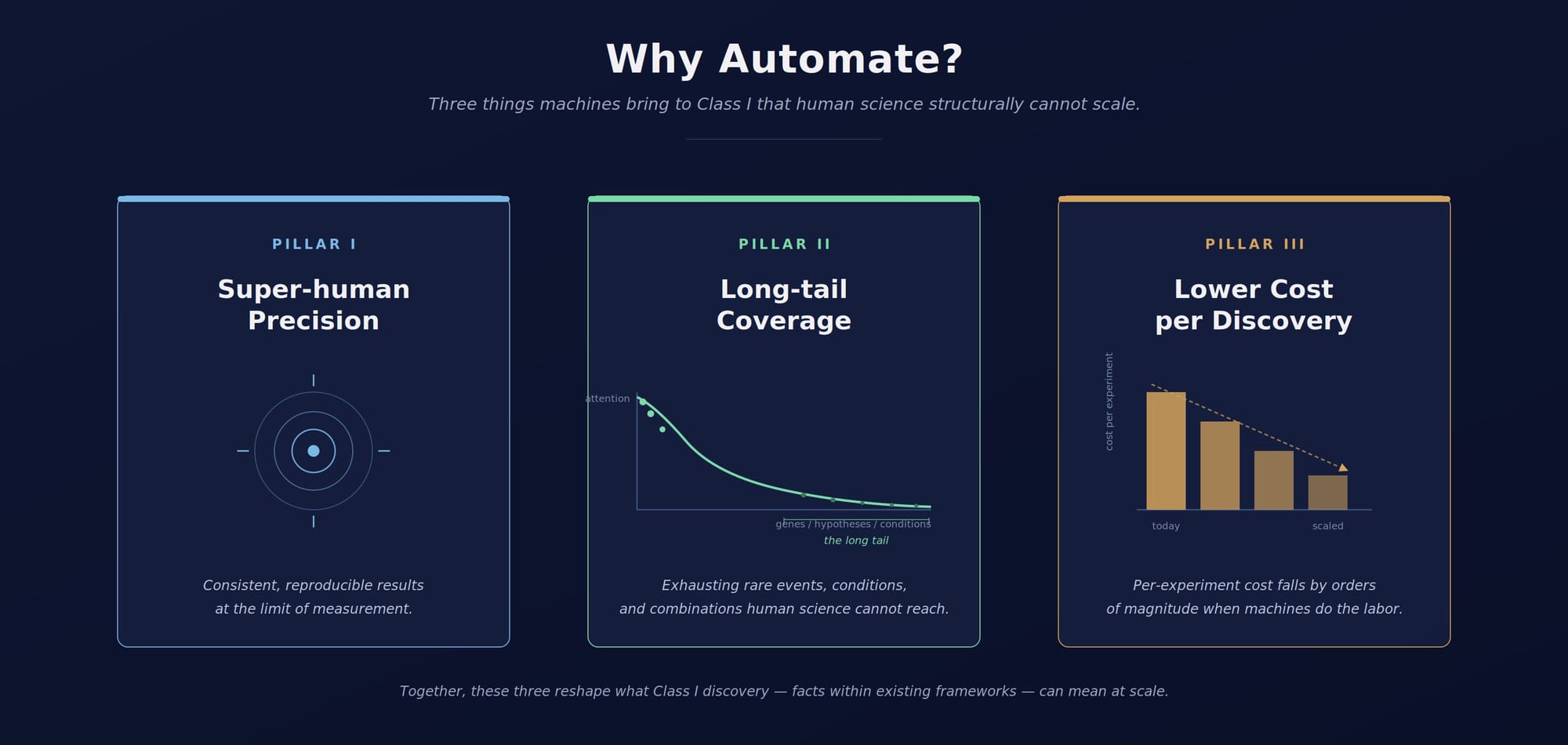
TREM2 の事例は、まさにそれだった。TREM2 は Class I の発見である —— 特定の遺伝子と特定の疾患との関係についての一つの事実。それが数十年のあいだ未発見のまま残されたのは、人間の注意経済がそこに賭けることを構造的に拒んだからである。Stoeger らが報告した 96.8% という数字 (Stoeger et al., 2018) は、こうした未発見の事実がほかにも大量に控えていることを示している —— ゲノムのロングテール、化学空間の未踏領域、材料の組成の組み合わせ、いかなる単独の研究室も時間を割けない条件と組み合わせの中に。その大半は Class I だ。その大半は、価値がある。だがその大半は、いまの paradigm のもとでは、発見されない。
自律的な発見システムが Class I のロングテールを、機械にしかできない規模・精度・一貫性で取り組むだけでも、それは科学の在り方を変える。Class II や Class III が、もし来るとしたら、それはさらに先の話になる。後の節で戻ってこよう。
もう一つの意味で、答えやすい問い
三つのクラスの整理は、「機械は発見できるか」がそもそもどういう種類の問いなのか、なぜ Turing の問いより一つの意味で答えやすいのか、を明らかにしてくれる。
Turing の問いを真剣に追い詰めていくと、「思考とは何か」という哲学の問題に行きつかざるをえなかった。「この機械は本当に思考しているのか?」を真剣に押し進めると、最終的には哲学の深い水域に降りていくことになる。意識とは何か。理解とは何か。意味とは何か。1980 年に John Searle が提示した「中国語の部屋 (Chinese Room)」の議論は、この点を鋭くついていた。中国語の質問が紙片で部屋に入り、中の人物が完全な記号操作の規則書に従って答えを書き、紙片で返してくる。外から見ると、部屋は中国語を理解しているように見える。だが、中の人物は中国語をひとつも理解していない。Searle の主張は、こういうことだった —— あるシステムが「思考しているように見える」出力をしていても、その内部に理解と呼べるものは何ひとつないかもしれない (Searle, 1980)。この思考実験について、私たちは 45 年論じ続けてきた。決着はついていない。これからもつかないだろう。
「発見」は、その哲学の深みに降りていく必要がない。発見には、外から測れる帰結がある。発見は三つのクラスのすべてにおいて、検証可能で、意義のある、新しい知識を生み出す。科学者集団は、それが本当に新しい発見かどうかを判定する実践を、長く不完全ながらも積み上げてきた。山中による iPS 細胞の樹立は、本物の発見だった (Takahashi & Yamanaka, 2006)。Charpentier と Doudna による、CRISPR-Cas9 をプログラム可能な編集ツールとして使えるという理解は、本物の発見だった (Jinek et al., 2012)。ヒッグス粒子の検出は、本物の発見だった。これらの判定はどれも、発見した主体が人間だったか、機械だったか、両者の協働だったか、には依存していない。
これが、「機械は発見できるか」を 実証的な (empirical) 問いだと私が言うときに意味することだ。実証的とは、答えが定義の議論ではなく、世界のなかの 証拠 によって決まる、という意味である。「発見とは本当のところ何か」について合意が取れていなくても、発見が起きたときに、それが起きたと認めることはできる。判定の方法は、科学者集団が常にやってきたとおり —— 結果を眺め、それを試し、その帰結に照らして、受け入れるか拒否するかを決める。
グランドチャレンジには、満たすべき二つの条件がある。一つは、分野全体を組織化できるくらい野心的であること。もう一つは、進展を測定できるくらい具体的であること。「機械は発見できるか」は、この両方を満たしている (Kitano, 2016, 2021)。
私たちは、もう全体を見渡せない
「いま」この問いを立てる理由は、もう一つある。それは、もっと差し迫った理由だ。
生命科学の分野では、毎年およそ 200 万本の論文が発表されている。最も活発な分科では、1 日に 1,000 本を超える。これを全部読み切れる科学者はいない。全体像として整理できる人もいない。重要なつながりを見抜ける人もいない。私たちは、誰も全体像を見渡せないほど巨大な「知識の大聖堂」を建てた。無数の科学者が、世代をまたいで、少しずつ積み上げてきた構築物である。そして、その聖堂のなかを、近場の目印を頼りに歩き回っている。全体の形が見えないまま。
これは情報過多 (information overload) の話ではない。もっと厄介なものだ —— 構造的ミスアライメント (structural misalignment) である。
しかも、この構造的ミスアライメントは抽象的な話ではない。実際に数字で示せる現象である。ヒトゲノムには、注釈の付いた遺伝子がおよそ 40,000 ある。そのうち 100 個をランダムに選び、PubMed を使って、各々の遺伝子に関する論文の数を数えてみると、際立ったパターンが現れる —— 引かれた論文のうち 96.8% が、よく研究された一握りの遺伝子に集中している。これは、Stoeger らがおよそ 19,000 のタンパク質コード遺伝子の全体について、系統的なバイアスとして報告したパターンと一致する (Stoeger et al., 2018)。
このバイアスを説明するのは、難しくない。そして、説明が簡単なこと自体が、問題の一部である。
科学者も、他の多くの人と同様に、成功したい。貢献したいと思っている。すでに重要そうに見える遺伝子に取り組むのは、キャリア戦略として理にかなっている。重要性のシグナルがあらかじめ立っていれば、研究費もつきやすい、レビュアーもつきやすい、引用もつく、学生もつく。同じ力学は、もっと最初の段階、研究テーマを選ぶ瞬間にもはたらく。研究者は、重要そうに見える問題に引き寄せられる —— 自分が意味のある仕事をしたいから、そして、何が意味あるかをすでに認識してくれる制度が、その仕事を支えてくれるから。これは悪徳ではない。むしろほとんどの場合、美徳だ。だが、これを世界中の研究者集団のレベルで足し合わせると、注意は すでに目に見えて重要なもの に強く集中する。
逆向きに見れば、こうなる。ロングテールの遺伝子 —— まだ何の重要性のシグナルも立っていない遺伝子 —— に取り組むことは、個々の研究者にとって、合理的とは言えない賭けである。期待される見返りは小さい。研究費の申請書は書きにくい。論文の掲載先も見つけにくい。仮にその遺伝子が本当に重要だと判明したとしても、その判明までに 15 年かかるかもしれない。ほとんどのキャリアは、それだけの遅れを吸収できない。だから、ロングテールは耕されない —— 調べた上で「重要でない」と判断したからではなく、そもそも調べられていないからだ。
これは厳密な意味で、人間の科学における認知的かつ社会的なバイアス である。個々の科学者の失敗ではない。人間の科学者は、キャリアと寿命に縛られ、評価を気にし、長期のリスクには手を出しにくい —— そういう存在として、構造的にこういうバイアスを持つ。それは予測可能なパターンだ。
このバイアスのコストは、理屈の上の話ではない。TREM2、ミクログリア上の受容体で、その稀な変異は遅発型アルツハイマー病のリスクをほぼ倍にすると今では分かっている (Guerreiro et al., 2013; Jonsson et al., 2013) —— この遺伝子は、数十年のあいだロングテールに置かれたままだった。実質、誰にも読まれずに。同じような事例が TREM2 だけだとは、考えにくい。96.8% という数字は、似たような事例が他にも大量にあることを示している。
このパターンが偶然でないなら —— 認知の作り、社会の構造、経済のインセンティブのなかで人間の科学者が動くとき、注意の配分にはこういう歪みが出ると予測できるなら —— このゆがみは、いまの paradigm の内側からは直せない。なぜなら、その paradigm こそが、ゆがみを生み出したものだからだ。
Discovery Engine とは何を意味するか
このブログのタイトルは、比喩であると同時に、技術的な提案でもある。
比喩として。18 世紀の終わり、蒸気機関は製造業を産業化した。AI とロボティクスを組み合わせた、閉ループの自律的な実験システムは、発見そのものを産業化するかもしれない。発見は、構造的にずっと前産業的な営みのままだった —— 個々の熟練した個人が、一つの仮説ずつ進める、一人の認知の帯域に縛られた営み。エンジンは、そこから先に来るものだ (Kitano, 2016, 2021)。
そのピースは、すでに揃いつつある。Ross King のロボット科学者 Adam & Eve は、仮説 → 実験 → 修正という閉じたサイクル全体を、限定的な領域で自律化できると示した初期のデモンストレーションである (King et al., 2009; Sparkes et al., 2010)。AlphaFold は、タンパク質の構造という、人間の研究者が一生かけても全体には到達できない巨大な問題を、一つの AI システムが網羅的に解けると示した (Jumper et al., 2021)。AlphaGo とその後継は、適切に設計された機械の探索が、人間の名人なら検討しなかったような手を、人間の直観が必要だとされていた空間のなかで、見出せると示した (Silver et al., 2016)。これらは、ピースである。エンジンそのもの —— これらの能力を統合し、規模を伴って閉ループで動かす構造 —— は、まだ存在しない。私はそれを Warp Drive for Scientific Discovery と呼んできた。これを、作る必要がある。
技術的な提案として。このエンジンは、具体的な目標として Nobel Turing Challenge という形をとる —— 2050 年までに、ノーベル賞に値する科学的発見を、高い自律度で行う AI システムを作る、という目標である (Kitano, 2021)。賞そのものが目的ではない。賞は、ものさしだ。私たちが気にかけているのは発見の 質 であり、ノーベル賞は、現存するなかでは最も分かりやすい、その代理指標 (proxy) である。
このチャレンジは、「機械は発見できるか」という問いを、具体的な形にしたものだ。問いをただの願望ではなく、検証可能なものに変える装置である。そしてそれは、人工知能におけるグランドチャレンジの系譜のなかにある —— 1950 年代のチェスを指す機械から、Deep Blue、AlphaGo、そして RoboCup へと続く系譜のなかに (Kitano et al., 1997)。それぞれのチャレンジは、結局のところ、議論ではなく demonstration によって答えられてきた。Nobel Turing Challenge も、同じように答えられるのではないかと、私は思っている。

このブログは、その内実を一つずつ展開していく。
- 限界論 —— なぜ人間の科学が、自分自身の構造的な限界に突き当たっているのか。
- Connecting Distant Dots —— 遠く離れた分野や知識を繋げて発見に至る経路。
- アーキテクチャ —— 閉ループの自律的な発見システムとは、具体的に何で構成されるのか。
- ベンチマーク —— Nobel Turing Challenge が何を試すのか、どう判定するのか。
- 認識論 —— 機械が科学を行うようになったとき、科学そのものは何に なる のか。
- 人間の役割 —— 人間の科学者は、もはやエンジンの主体ではなくなったとき、どんな役割を担うのか。
これは、機械が人間をきれいに置き換える物語でもなければ、機械と人間がきれいに協働する物語でもない。多くの場合 —— おそらくは大半の場合 —— 人間は、運転のループの外側に座ることになる。機械が文献を読み、仮説を立て、実験を設計し、実行し、検証する。私たちを通さずに。それでも、人間の科学者に残る役割はある。具体的なものだ。今の構図が示唆するよりも、それは絞り込まれている。
一つ目の役割は アライメント (alignment) だ —— 機械が 発見できる もののうち、どれが人間にとって 意味のある ものかを決め、そのうちどれを表に出し、優先順位をつけ、応用するかを判断すること。二つ目は ニッチ (niches) —— 機械システムがコスト、身体性、アクセス、固有性の理由で届かない、科学の地形のなかの一帯。この二つは、慰めの賞ではない。むしろ、探索と処理能力がボトルネックでなくなったとき、最も希少になり、最も価値が出る役割である。
一つの予言
Computing Machinery and Intelligence のなかで、Turing は一つの予言を残した。50 年のうちに、機械は模倣ゲームで、平均的な質問者をたいてい騙せるくらいの腕前になるだろう、と。どう穏当に読んでも、この予言は当たった、と言える。
私も、自分の予言を一つ書き残しておきたい。
Turing の問いが議論ではなく demonstration によって答えられたのと同じように、「機械は発見できるか」もまた、同じ仕方で答えられるだろう。ある日、科学者集団がひとつの発見を「本物だ、意義がある」と認める。そして振り返ってみると、その発見の中心には、人間が一人も関わっていなかったことに気づく。
その日に、この問いは過去形になる。
そしてその日に、もっと本質的な問いに向かい合うことになる。
機械による発見は、私たちの発見と似たものになるのか、それとも、まったく別の何かになるのか。
この問いには、出発点としての答えがすでに立てられる。それだけでも、十分に変革的だ。自律的なシステムが、人間の科学が構造的に過小評価してきた事実 —— Class I のロングテール —— を組織的に耕すなら、これから数十年で生み出される検証済みの新しい知識の量は、これまでの paradigm が歴史を通じて生み出してきた量を、上回るだろう。TREM2 のような空白は、機械的な根気で、次々に埋められていく。それだけで、科学が到達できる範囲は、革命的に拡がる。
だが、その先にある可能性は、もっと深い。機械は Class I で止まらないかもしれない。人間のどのチームにも、それを組み上げるだけの帯域がなかった領域で、Class II の枠組みを構築し始めるかもしれない —— 構造的に分かれてきた複数の文献を、機械はまたいで読むことができるからだ。そして、その極限において、機械は 新しい意味次元 (new semantic dimensions) を作り始める かもしれない —— 世界を切り分ける新しい仕方、現象を整理する新しい軸、「問うに値する問い」のカテゴリそのものの新しい設計を。発見が、その最も遠い射程において、科学の概念空間そのものを広げる営みなのだとすれば、十分に有能な発見する機械は、その拡張の側にも回るだろう。
私の直感では、機械による発見は、私たちのものとは違って見えるはずだ。網羅的な探索で進み、いかなる人間のチームも組み合わせたことのない文献を組み合わせ、人間の注意検出が体系的に取りこぼす特徴に目を向けるシステムは、私たちと同じ洞察に、同じ経路で辿りつくことはない。機械は、私たちと同じ場所には辿りつかない。だが、まったく違う場所に辿りつくわけでもない。私たちが行こうとした場所の近くに、別の道から、辿りつく。最初は、それが見つけたものの一部は、私たちには認識できないだろう —— 発見が間違っているからではない。その発見が住む意味次元が、まだ私たちのものになっていないからだ。
そのとき、私たちが学ぶのは、機械についてのことだけではない。発見そのものについて —— 私たちがこれまで自分自身で発見してきたとき、いったいどんな種類の営みを行ってきたのか —— という、自分自身についての発見でもある。
機械はすでに、人間が思いつかなかった問いを立て始めている。
新しい発見のパラダイムが、出現する。
このポストが、どう書かれたかについて
Discovery Engine には、もう一つの前提がある。脚注に埋もれさせず、最初に明示しておきたい。
このブログは、人間の著者が AI システムと深く協働しながら書いている。主たる共著者は Claude (Anthropic)、補助的な共著者として Gemini (Google) を、そして cross-check や別アングルからの言い直し、参照作業に ChatGPT (OpenAI) を用いている。下書きは私たちのあいだを行き来する。議論はストレステストにかけられ、構造は組み直され、表現は研ぎ澄まされていく。最終的な編集判断 —— 何を言い、何を残さないか —— は、私のものである。より広い意味での「思考」は、共有されている。
これは意図的であり、テーマと整合している。
機械が「発見」できるかを問うブログが、それを「人間ひとりで書いた」ふりをするのは、筋が通らない。だから、ありのままに書く。これが、2026 年の時点で、人間と機械の本気の協働が 「書く」という作業のなかで 実現している姿である。
「書く」というのは、人間と機械が一緒に取り組める作業のなかで、最も易しい部類のものだ。「発見する」というのは、それより遥かに難しい。そして、このブログが向かっていくのは、その「発見する」という作業のほうである。
あなたが今読んでいるものは、すでに可能になっていることの、ささやかな実例である。これから続く投稿は、まだ可能になっていないこと —— そこに辿りつくには何が必要か —— についての記述になる。
北野宏明 (Hiroaki Kitano)
共著: Claude (Anthropic, 主) / Gemini (Google, 副) / ChatGPT (OpenAI)
本ポストのLab Notebook(英語)に、ソース資料、推敲履歴、AI 入力、そして学んだことを記録している。
References
Guerreiro, R., et al. (2013). TREM2 variants in Alzheimer's disease. New England Journal of Medicine, 368(2), 117–127. https://doi.org/10.1056/NEJMoa1211851
Jinek, M., Chylinski, K., Fonfara, I., Hauer, M., Doudna, J. A., & Charpentier, E. (2012). A programmable dual-RNA-guided DNA endonuclease in adaptive bacterial immunity. Science, 337(6096), 816–821. https://doi.org/10.1126/science.1225829
Jonsson, T., et al. (2013). Variant of TREM2 associated with the risk of Alzheimer's disease. New England Journal of Medicine, 368(2), 107–116. https://doi.org/10.1056/NEJMoa1211103
Jumper, J., et al. (2021). Highly accurate protein structure prediction with AlphaFold. Nature, 596, 583–589. https://doi.org/10.1038/s41586-021-03819-2
King, R. D., et al. (2009). The automation of science. Science, 324(5923), 85–89. https://doi.org/10.1126/science.1165620
Kitano, H., Asada, M., Kuniyoshi, Y., Noda, I., & Osawa, E. (1997). RoboCup: The robot world cup initiative. AI Magazine, 18(1), 73–85. https://doi.org/10.1609/aimag.v18i1.1276
Kitano, H. (2016). Artificial intelligence to win the Nobel Prize and beyond: Creating the engine for scientific discovery. AI Magazine, 37(1), 39–49. https://doi.org/10.1609/aimag.v37i1.2642
Kitano, H. (2021). Nobel Turing Challenge: Creating the engine for scientific discovery. npj Systems Biology and Applications, 7, 29. https://doi.org/10.1038/s41540-021-00189-3
Kuhn, T. S. (1962). The Structure of Scientific Revolutions. University of Chicago Press. University of Chicago Press
Searle, J. R. (1980). Minds, brains, and programs. Behavioral and Brain Sciences, 3(3), 417–457. https://doi.org/10.1017/S0140525X00005756
Silver, D., et al. (2016). Mastering the game of Go with deep neural networks and tree search. Nature, 529, 484–489. https://doi.org/10.1038/nature16961
Sparkes, A., et al. (2010). Towards Robot Scientists for autonomous scientific discovery. Automated Experimentation, 2, 1. https://doi.org/10.1186/1759-4499-2-1
Stoeger, T., Gerlach, M., Morimoto, R. I., & Amaral, L. A. N. (2018). Large-scale investigation of the reasons why potentially important genes are ignored. PLOS Biology, 16(9), e2006643. https://doi.org/10.1371/journal.pbio.2006643
Takahashi, K., & Yamanaka, S. (2006). Induction of pluripotent stem cells from mouse embryonic and adult fibroblast cultures by defined factors. Cell, 126(4), 663–676. https://doi.org/10.1016/j.cell.2006.07.024
Turing, A. M. (1950). Computing machinery and intelligence. Mind, 59(236), 433–460. https://doi.org/10.1093/mind/LIX.236.433
本記事の引用
Kitano, H. (2026). 機械は発見できるか (Can Machines Discover?). Discovery Engine, 2026 年 5 月 31 日. https://thediscoveryengine.ai/can-machines-discover-ja/
BibTeX:
@misc{kitano2026machines-ja,
title = {機械は発見できるか (Can Machines Discover?)},
author = {Kitano, Hiroaki},
year = {2026},
month = {May},
day = {31},
howpublished = {\url{https://thediscoveryengine.ai/can-machines-discover-ja/}},
note = {Discovery Engine, Post \#1 (Japanese version)}
}


